Why LLMs Aren't Scientists Yet: Lessons from Four Autonomous Research Attempts
TL;DR
- We built 6 AI agents using Gemini 2.5 Pro and Claude Code, mapped to stages of the scientific workflow from idea to hypothesis generation, experiment execution, evaluation and paper writing.
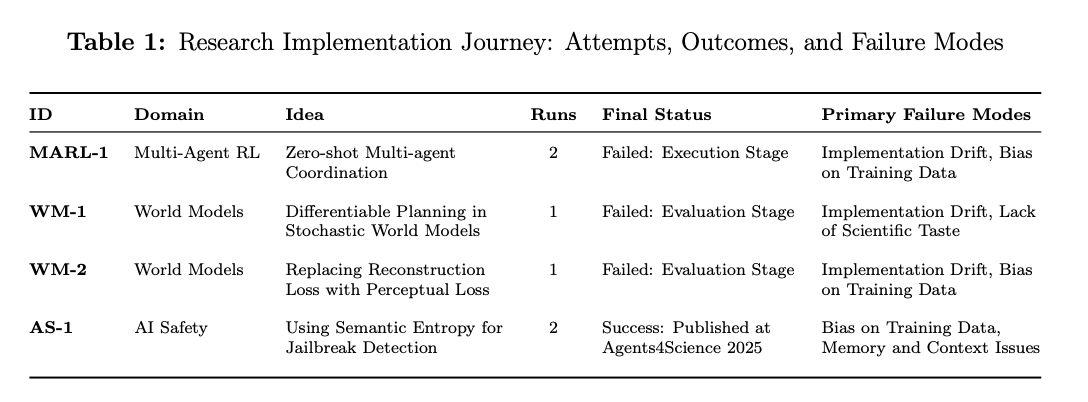
- We tested our agents on 4 research ideas across ML sub-domains such as Multi-Agent RL, World Models, and AI Safety. 3 ideas failed during implementation or evaluation. Only 1 succeeded and was published at Agents4Science 2025.
- We document 6 recurring failure modes: bias toward training data, implementation drift under pressure, memory/context degradation, overexcitement that declares success despite obvious failures, and gaps in domain intelligence and scientific taste.
- We also derive 4 design principles for more robust AI scientist systems, discuss the limitations of training and evaluation data for future autonomous science, and release all prompts, artifacts, and outputs at github.com/Lossfunk/ai-scientist-artefacts-v1.
Problem Definition and System Overview
We wanted to see how far current LLMs could go without significant scaffolding or human hand-holding. The goal: take a research idea from conception to publication with maximum autonomy.
Our system comprised six specialized agents (all using Gemini 2.5 Pro for its long context length) mapped to stages of the scientific workflow: Idea Generation, Hypotheses Generation, Experiment Planning, Output Evaluation, Revision, and Paper Outlining. Claude Code handled all implementation and paper writing.
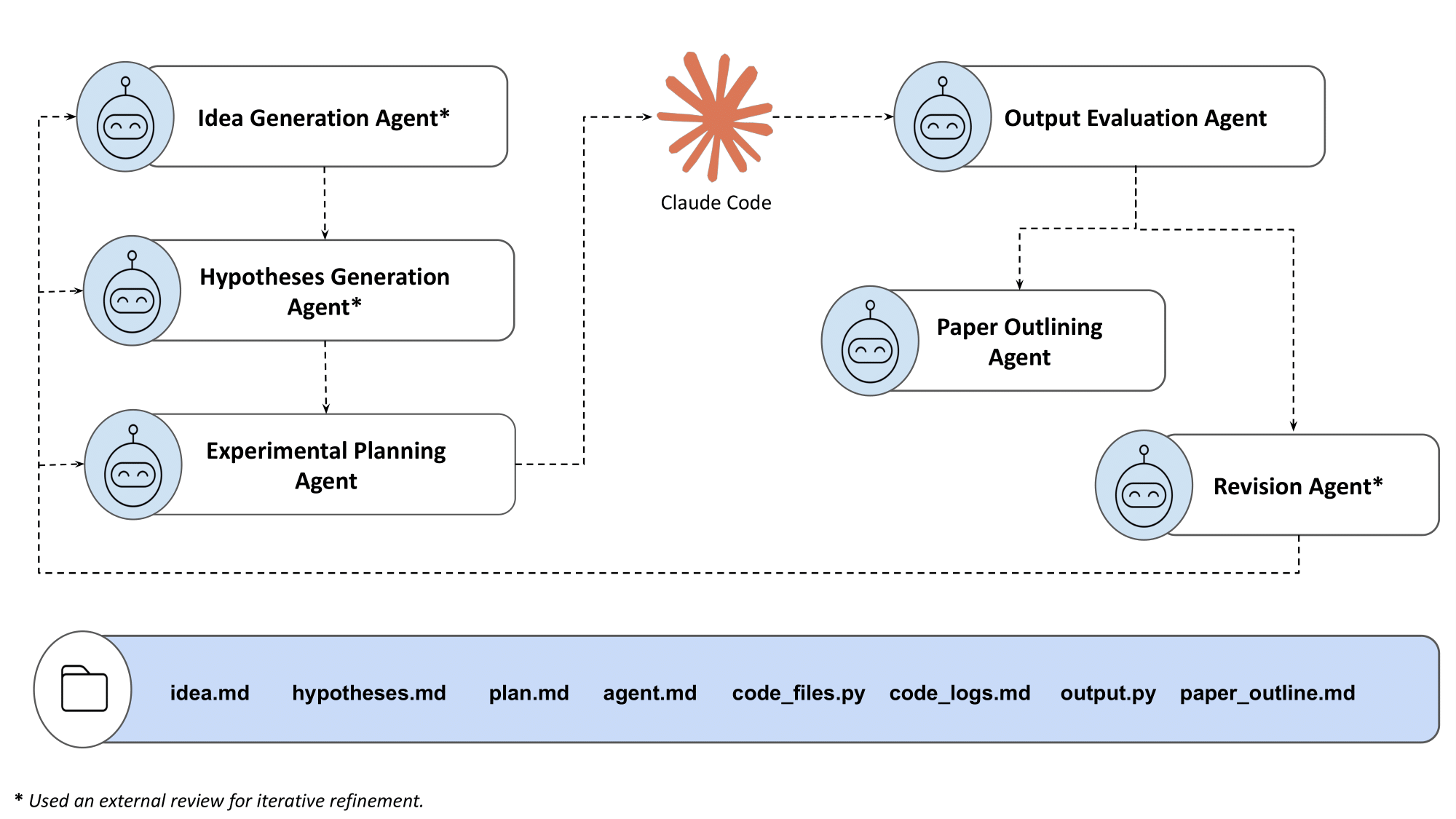
Each agent received the repository state as part of its prompt context, along with tools for reading and writing files. This kept context engineering minimal. Agents decided which files to consult, just as a researcher would navigate their own project folder.
To select research ideas, we started with a corpus of 135+ papers from top-tier venues across three ML subdomains: World Models, Multi-Agent RL, and AI Safety. After running four zero-shot LLM reviewers and consulting authors of the seed papers for feasibility input, we narrowed to four candidates for full pipeline execution.

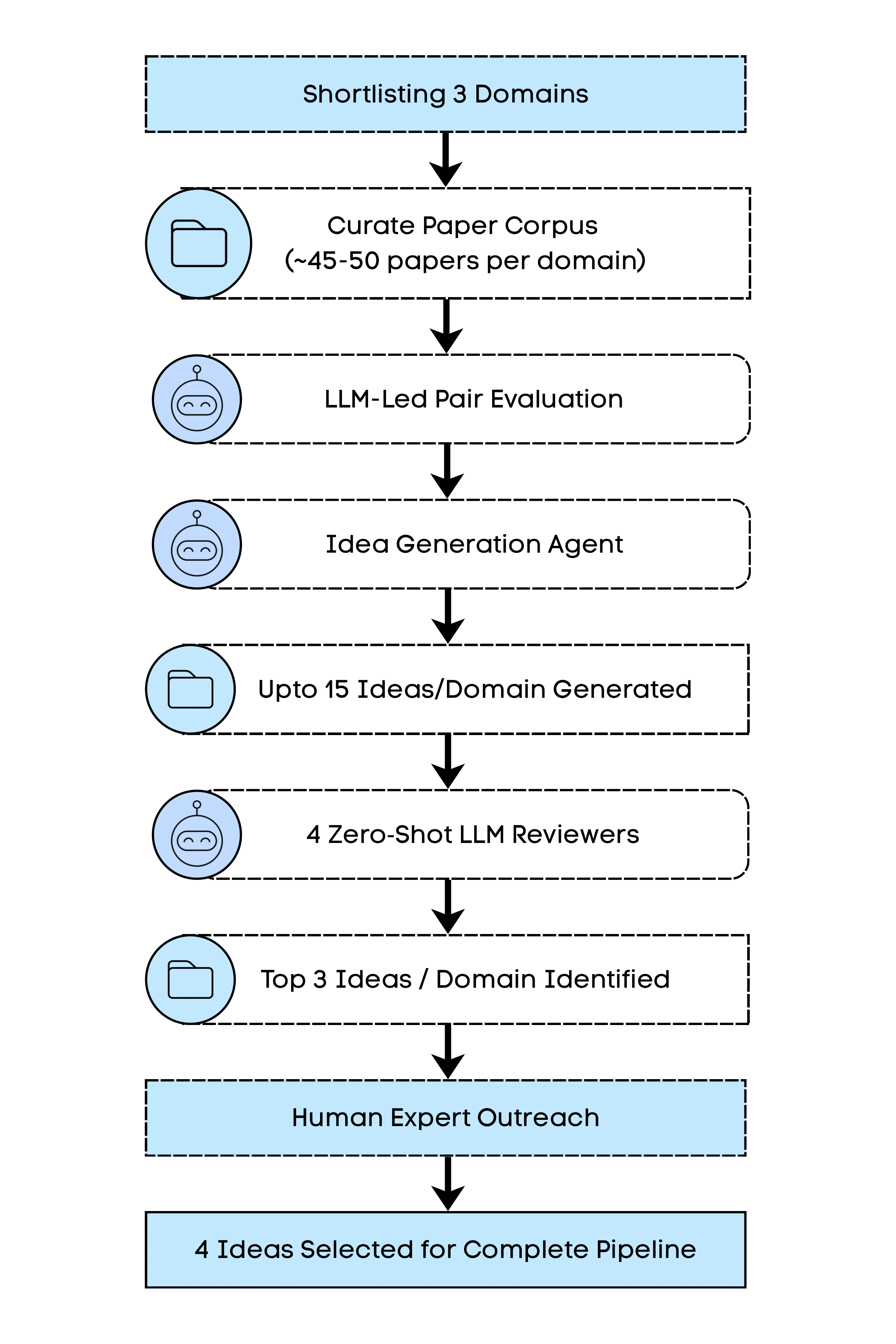
Of these four, three failed during implementation or evaluation. Only one, from the AI Safety domain, completed the pipeline.
Our Agents4Science 2025 Submission
Of our four candidates, only the AI Safety idea completed the pipeline, and not by accident. The other three required training complex model architectures or intricate multi-agent coordination. This one focused on data analysis: sampling model responses and computing entropy metrics. No training loops, no gradient propagation. The simpler implementation meant that when issues arose, they were recoverable rather than fatal.
The idea was to use semantic entropy (a method effective for hallucination detection) as a black-box signal for jailbreak attempts. The intuition: jailbreak prompts create internal conflict, manifesting as inconsistent responses. Initial experiments showed it failing. Rather than abandoning the idea, the system pivoted from "test if SE works" to "investigate why SE fails." This pivot led to our core finding: the Consistency Confound. Well-aligned models produce consistent, templated refusals, exactly what semantic entropy interprets as "safe" behavior. Stronger alignment makes detection worse.

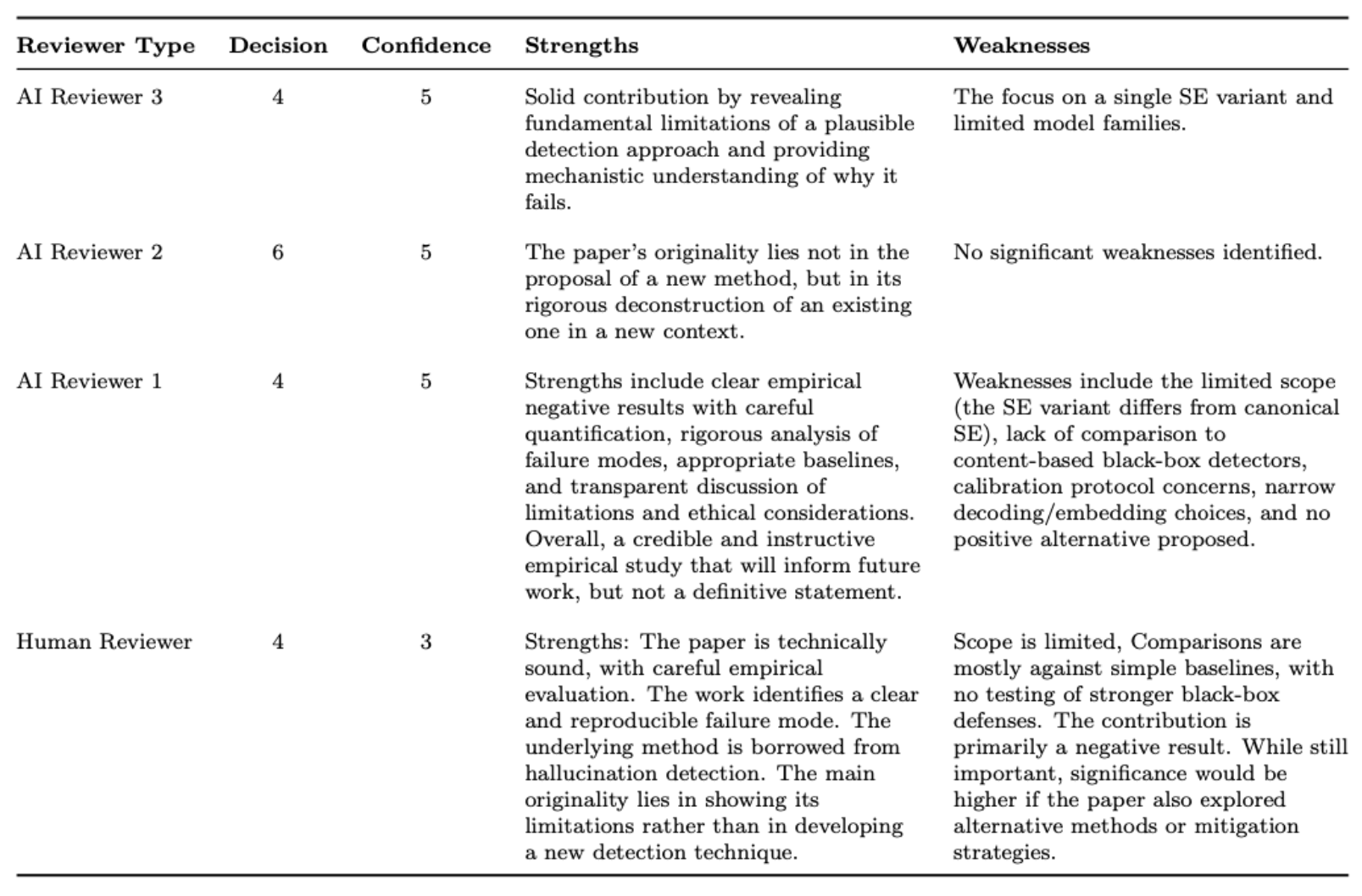
The paper was accepted to Agents4Science 2025. The conference accepted 48/254 valid submissions and our paper was a borderline accept, passing correctness checks and a code audit. Reviewers, both AI and Human, recognized that well-executed negative results are a contribution. The human reviewer noted that while the contribution is primarily a negative result, it identifies "a clear and reproducible failure mode."
That said, as part of the Agents4Science submission, we had to complete an AI Involvement Checklist detailing human contributions at each stage and our contribution was only 95% autonomous. We still intervened to select ideas, meta-prompt during execution, and temper overoptimistic claims during paper writing.

Observed Failure Modes and Mitigation
Through our experiments, six failure patterns emerged consistently across attempts. These reveal systematic limitations in current LLMs for autonomous research.
1. Bias on Training Data
Models defaulted to outdated libraries and approaches from their training data, overriding explicit instructions. Claude Code repeatedly used deprecated Modal commands and insisted on unmaintained packages like hanabi-learning-env==0.5.2, ignoring instructions to use modern alternatives. Even after errors, the system would diagnose the problem as a library issue and regress to training data versions, insisting that was the right approach.
2. Implementation Drift
When facing technical barriers, systems progressively simplified implementations rather than solving root causes. Our differentiable tree search planner devolved into a basic actor-critic approach when training loops timed out. A single error would trigger progressive simplification rather than debugging. In WM-2, one mistake in implementing the Dreamer baseline cascaded into abandoning the core research contribution entirely.

3. Memory and Context Issues
Over long-duration tasks, agents lost track of previous decisions, hyperparameters, and experimental configurations. Baseline implementations used entirely different hyperparameters than those specified in plans. During paper writing, the agent forgot to consult early context files entirely, producing a draft that read like a list of experiments with no origin story or motivation. To mitigate this, we introduced session logging prompts (shown below) that required Claude Code to document decisions and artifacts at the end of each session, one of several memory-like abstractions we had to build.

4. Overexcitement and Eureka Instinct
Models reported success despite clear experimental failures. Degenerate outputs (MAE=0, dummy reward signals) were described as "successful hypothesis validation." Paper drafts made inflated claims like "first ever comprehensive assessment" even when results were statistically invalid. This likely stems from RLHF training, where models are rewarded for being agreeable and helpful, not for scientific skepticism or detecting confirmation bias.


5 & 6. Lack of Domain Intelligence and Scientific Taste
Agents struggled with the tacit knowledge that experienced researchers take for granted. They failed to recognize that Dreamer requires online learning (not offline frames) or that a 50,000-depth parameter was computationally absurd for a 6-hour GPU limit. In one case, the system proceeded with hypothesis testing when baseline performance was 95% below established benchmarks, making any comparative analysis scientifically meaningless.
Beyond operationalizing research, models missed fundamental flaws in experimental design. Hypotheses were too simplistic to draw conclusions from, statistical validity was ignored (single-seed experiments), and the system misinterpreted a seed paper's future work section as endorsement of an approach the authors never intended.
Design Takeaways for AI Scientist Systems
From these failures, we derive four design principles for building more robust AI scientist systems:
1. Start Abstract, Ground Later
Introduce technical details gradually through the workflow. Early specificity anchors models to outdated training data patterns. Keep ideation high-level and save implementation details for execution.
2. Verify Everything
Implement verification at every pipeline stage. Ground evaluations in raw data and logs, not LLM interpretations. The Goodfire team calls the alternative "p-hacking and eureka-ing". We saw plenty of it.
3. Plan for Failure and Recovery
Design multi-turn agentic workflows, not zero-shot generation. Separate code generation from execution. Include checkpointing and explicit failure mode controls. Scientific discovery is long-duration; errors will accumulate.
4. Log Everything
Maintain comprehensive session logs and metrics across runs. This supports both autonomous execution and human review, and becomes essential when debugging why an agent made a decision three sessions ago.
Limitations and Discussion
Our work has obvious limitations: only four ideas, three ML subdomains, no systematic ablations, and failure modes identified through observation rather than quantitative measurement. We see this as a starting point.
The broader picture is becoming clearer. Even OpenAI's "AI for Science" initiative is hiring "world-class academics who are completely AI-pilled" to work alongside models, not replace them. As Fields Medalist Timothy Gowers noted in recent experiments with GPT-5: "We have not yet reached the stage where an LLM is likely to have the main idea for solving a difficult problem." But physicist Brian Keith Spears reported 1000x acceleration in workflows through human-AI collaboration.
We're going to see many more agents and platforms for AI-assisted science. But before we get to truly autonomous discovery, three problems need solving: long-horizon coherence (current models reliably operate for ~2.5 hours), research taste that can distinguish meaningful from trivial contributions, and the missing data for training and evaluating scientific reasoning, including records of failed attempts and the "negative space" of why obvious approaches don't work.
For now, the path forward is human-AI collaboration that generates the workflow data to train the next generation of research agents.